很多时候,产品设计人员或者产品经理都会被滚滚而来的各种需求淹没。到底哪些用户是用户真正喜欢的需求呢?哪些是一些伪需求,或者是负面的需求呢?这都需要产品经理对其进行斟酌与分辨。近日,NVIDIA高级设计师Brian O\'Neill在Medium上发表了一篇文章介绍了一个非常有用的分析模型——卡诺模型(Kano Model )
来源:TXD技术体验设计(公众号)
作者:澄曦

是不是曾发生想到或用户提出了很多需求,但不知道怎么辨识真正有用的需求,或排期优先级怎么安排的情况?以下介绍一种定性研究,透过问卷调研的方式来了解需求属型与必要性。
一、KANO 模型简介
KANO 卡诺模型是由日本狩野纪昭(Noriaki Kano)博士所提出,主要用途是了解需求实现与用户满意度之间的关系,作为产品需求分析与优先级排序的参考依据。KANO 模型定义了三个层次的顾客需求:基本型需求、期望型需求和兴奋型需求,这三种需求根据绩效指标分类就是基本因素、绩效因素和激励因素。
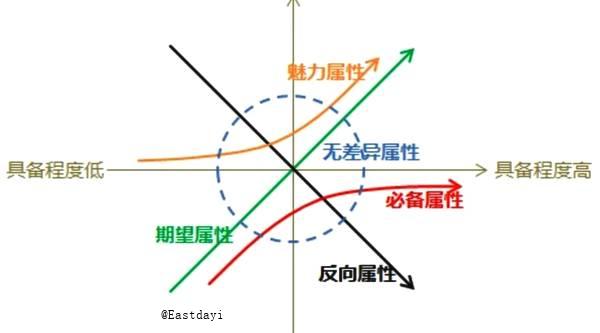
在 KANO 模型中,将产品和服务的质量特性分为五种类型:
魅力属性:让用户意想不到,如果不提供此需求,用户满意度不会降低;当提供此需求,用户满意度会有很大的提升。
期望属性:当提供此需求,用户满意度会提升;当不提供此需求,用户满意度会降低。
必备属性:当提供此需求,用户满意度不会提升;当不提供此需求,用户满意度会大幅降低。
无差异属性:无论提供或不提供此需求,用户满意度都不会发生改变,用户根本不在意。
反向属性:用户根本没有此需求,提供后用户满意度反而会下降。

二、KANO 模型分析法的基本步骤
步骤一:设计问卷调查表,实施有效的问卷调查
KANO 模型的问卷问法,是对每个质量特性都由正向和负向两个问题构成,分别测量用户在面对存在或不存在某项质量特性时的反应。问卷中的问题答案采用五级选项分别是:
我很喜欢:让你感到满意、开心、惊喜。
理应如此:你觉得是应该且必备的功能。
无所谓:你不会特别在意,但还可以接受。
勉强接受:你不喜欢,但可以接受。
我很不喜欢:让你感到不满意。

(备注:可疑结果通常不会出现,除非用户理解错误)
步骤二:问卷结果整理,进行数据分析
根据问卷结果进行 KANO 模型二维属性归属分析,可得出魅力属性、期望属性、必备属性、无差异属性、反向属性与可疑结果的功能属性归类百分比。除了对属性的归属探讨外,并通过百分比计算出 Better-Worse 系数,表示某功能可以增加满意或者消除很不喜欢的影响程度。
增加后的满意系数 Better/SI=(A+O)/(A+O+M+I)
消除后的不满意系数 Worse/DSI=-1*(O+M)/(A+O+M+I)
Better 的数值通常为正,代表如果提供某种功能属性,用户满意度会提升;正值越大越接近 1,表示对用户满意度提升的影响效果越大,上升越快。Worse 的数值通常为负,代表如果不提供某种功能属性,用户的满意度会降低;值越负向越接近-1,表示对用户满意度降低的影响效果越大,下降越快。 因此,根据 better-worse 系数,对系数绝对分值较高的功能/服务需求应当优先实施。

根据 better-worse 系数值,将散点图划分为四个象限:
第一象限期望属性:表示 better 系数值高,worse 系数绝对值也很高的情况,产品提供此功能,用户满意度会提升,当不提供此功能,用户满意度就会降低,应尽力去满足用户的期望型需求。
第二象限魅力属性:表示 better 系数值高,worse 系数绝对值低的情况,不提供此功能,用户满意度不会降低,但当提供此功能,用户满意度和忠诚度会有很大提升。
第三象限无差异属性:表示 better 系数值低,worse 系数绝对值也低的情况,无论提供或不提供这些功能,用户满意度都不会有改变,这些功能点用户并不在意。
第四象限必备属性:表示 better 系数值低,worse 系数绝对值高的情况,当产品提供此功能,用户满意度不会提升,当不提供此功能,用户满意度会大幅降低,说明这些功能是最基本的需求,必须要实现。
步骤三:数据解读,将结果落地实施
KANO 模型是对功能需求的优先级进行探索,具体情况还需要和业务方进行讨论,结合实际情况后制定可行的产品功能开发优先级顺序,以将调研结果落地实施。
三、实际操作案例说明
以下以掌上运维APP的问卷调研题目与统计数据作为实例,详细描述数据统计的过程与方式。
步骤一:设计问卷问题,发放问卷
编制问卷的时候,对每个功能都要有正反两道题来测,正反问题之间的区别需注意强调,防止用户看错题意,功能的解释要能简单描述该功能点,确保用户理解。采用单选矩阵的形式提供作答,举例如下所式:
题目:根据报警内容,“掌上运维”提供运维操作建议(如磁盘满了智能推荐执行日志清理等)。

步骤二:问卷统计,进行 KANO 模型二维属性归属分析
回收问卷后需要先进行数据的清洗,去除非有效的作答数据,接著根据 KANO 模型计算方式进行统计,首先需人为进行答题结果的统计计算,如有用户正向答题很喜欢,负向答题很不喜欢,则统计数字就会交叉落在最右边的第一个格子中,数字加1,已此类推进行数量的统计。

接著统计每种可能下的用户人数占总人数的百分比,来填入下表;之后将下表中标 A、O、M、I、R、Q 的格子中百分比相加,即可得到五种属性对应的百分比。本调查结果可以得到A魅力属性占比为42.1%,O期望属性占比9%,M必备属性占比1.2%,I无差异属性占比38.9%,R反向属性占比1.8%,Q可疑结果占比7%。

步骤三:计算 Better-Worse 系数,明确功能落点象限
依据六种属性的百分比,使用上方的计算公式来得出 Better-Worse 系数,Better系数为0.56,Worse系数为-0.11,并根据 better-worse 系数值,将散点图划分为四个象限,落点在于第二象限的魅力属性,发生于 better 系数值高,worse 系数绝对值低的情况,即表示不提供此功能,用户满意度不会降低,但当提供此功能,用户满意度和忠诚度会有很大提升。

步骤四:多个功能需求结果对比进行优先级排序
当多个需求进行调研统计后,从需求优先级排序来说,应先满足M必备属性功能,接著是去除R反向属性功能,再满足O期望属性功能,最后满足A魅力属性功能,不过还是要根据业务当下的需求与情况来做调整判断。